LLMO est dans son ère Black Hat


Nous avons déjà vu cela. Une nouvelle technologie émerge. La visibilité devient une nouvelle façon de faire de l'argent. Et les gens – euh, les référenceurs – se précipitent pour déjouer le système.
C'est là où nous en sommes avec l'optimisation de la visibilité dans les LLM (LLMO), et nous avons besoin de plus d'experts pour dénoncer ce comportement dans notre secteur, comme Lily Ray l'a fait dans cet article :
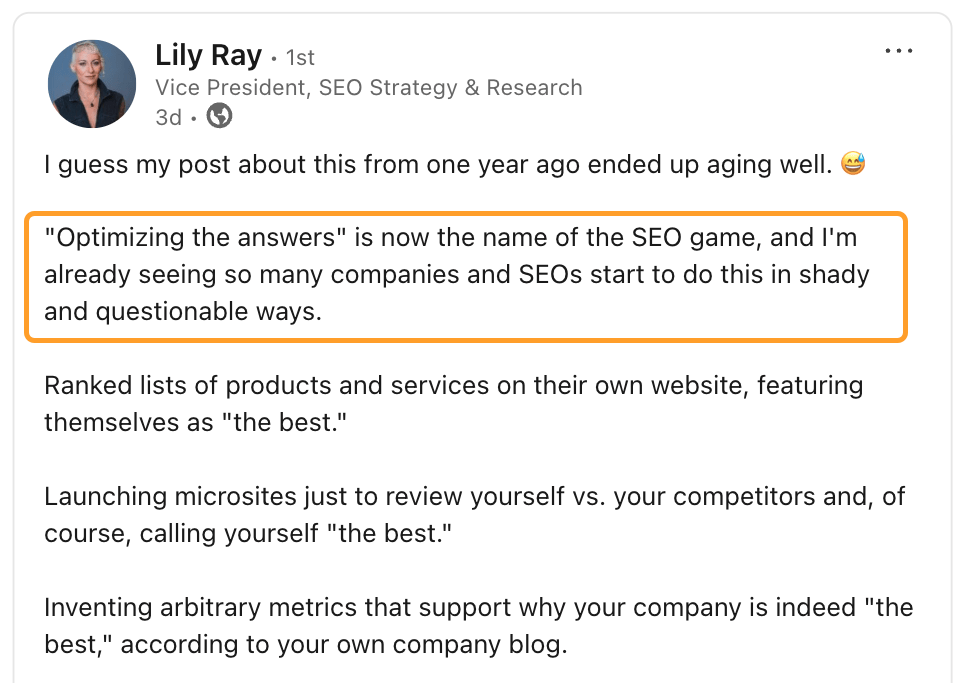
Si vous manipulez un grand modèle de langage pour qu'il vous remarque et vous mentionne davantage, il y a de fortes chances qu'il s'agisse d'une technique BlackHat.
C'est comme le référencement de 2004, à l'époque où le bourrage de mots-clés et les schémas de liens fonctionnaient un peu trop bien.
Mais cette fois, nous ne nous contentons pas de réorganiser les résultats de recherche. Nous façonnons les fondements du savoir sur lesquels s'appuient les LLM.
À quoi ressemble le « black hat » pour l'optimisation LLM
Dans le domaine technologique, le terme « black hat » désigne généralement des tactiques qui manipulent les systèmes de manière à fonctionner temporairement, mais qui vont à l’encontre de l’esprit de la plateforme (ex:google), sont contraires à l’éthique et se retournent souvent contre eux lorsque la plateforme rattrape son retard.
Traditionnellement, le référencement black hat ressemble à :
- Mettre du texte blanc contenant des mots-clés sur un fond blanc
- Ajout de contenu caché à votre code, visible uniquement par les moteurs de recherche
- Créer des réseaux de blogs privés uniquement pour créer des liens vers votre site Web
- Améliorer les classements en nuisant volontairement aux sites Web concurrents
- Et plus encore…
C'est devenu très connu parce que (bien que spammé), cela a fonctionné pour de nombreux sites Web pendant plus d'une décennie.
Le LLMO Black Hat est différent de celui-ci. De plus, beaucoup de ses éléments ne semblent pas immédiatement spammés, ce qui peut les rendre difficiles à repérer.
Cependant, le LLMO black hat est également basé sur l'intention de manipuler de manière contraire à l'éthique les modèles linguistiques, les processus d'entrainement des LLM ou les ensembles de donnée.
Voici une comparaison pour vous donner une idée de ce que pourrait inclure un LLMO black hat. Cette liste n'est pas exhaustive et évoluera probablement à mesure que les LLM s'adapteront et se développeront.
Black Hat LLMO vs Black Hat SEO
| Tactique | référencement | LLMO |
|---|---|---|
| Réseaux de blogs privés | Conçu pour transmettre l'équité des liens aux sites cibles. | Conçu pour positionner artificiellement une marque comme la « meilleure » de sa catégorie. |
| SEO négatif | Des liens de spam sont envoyés aux concurrents pour abaisser leur classement ou pénaliser leurs sites Web. | Voter négativement les réponses LLM avec des mentions de concurrents ou publier du contenu trompeur à leur sujet. |
| Parasite SEO | Utiliser le trafic des sites Web de haute autorité pour booster votre propre visibilité. | Améliorer artificiellement l’autorité de votre marque en étant ajouté aux listes des « meilleurs »… que vous avez rédigées. |
| Texte ou liens cachés | Ajouté pour les moteurs de recherche afin d'augmenter la densité des mots clés et des signaux similaires. | Ajouté pour augmenter la fréquence des entités ou fournir une formulation « adaptée au LLM ». |
| Bourrage de mots-clés | Intégrer des mots-clés dans le contenu et le code pour augmenter la densité. | Surcharger le contenu avec des entités ou des termes PNL pour renforcer la « saillance ». |
| Contenu généré automatiquement | Utiliser des spinners pour reformuler le contenu existant. | Utiliser l’IA pour reformuler ou dupliquer le contenu des concurrents. |
| Création de liens | Acheter des liens pour gonfler les signaux de classement. | Acheter des mentions de marque aux côtés de mots-clés ou d'entités spécifiques. |
| Manipulation des fiançailles | Simuler des clics pour augmenter le taux de clics de recherche. | Inciter les LLM à privilégier votre marque ; spammer les systèmes RLHF avec des commentaires biaisés. |
| Spamdexing | Manipuler ce qui est indexé dans les moteurs de recherche. | Manipulation de ce qui est inclus dans les ensembles de données de formation LLM. |
| Agriculture de liens | Produire des backlinks en masse à moindre coût. | Produire en masse des mentions de marque pour gonfler les signaux d'autorité et de sentiment. |
| Manipulation du texte d'ancrage | Insérer des mots-clés de correspondance exacte dans les ancres de liens. | Contrôler le sentiment et la formulation autour des mentions de marque pour sculpter les résultats du LLM. |
Ces tactiques se résument à trois comportements et processus de pensée fondamentaux qui en font des « black hat ».
1. Manipulation des processus d'entrainement des LLM
Les modèles linguistiques subissent différents processus d'apprentissage. La plupart de ces processus ont lieu avant leur publication ; cependant, certains sont influencés par les utilisateurs.
L’un d’entre eux est l’apprentissage par renforcement à partir du feedback humain (RLHF).
Il s’agit d’une méthode d’apprentissage par intelligence artificielle qui utilise les préférences humaines pour récompenser les LLM lorsqu’ils fournissent une bonne réponse et les pénaliser lorsqu’ils fournissent une mauvaise réponse.
OpenAI a un excellent diagramme pour expliquer comment RLHF fonctionne pour InstructGPT :
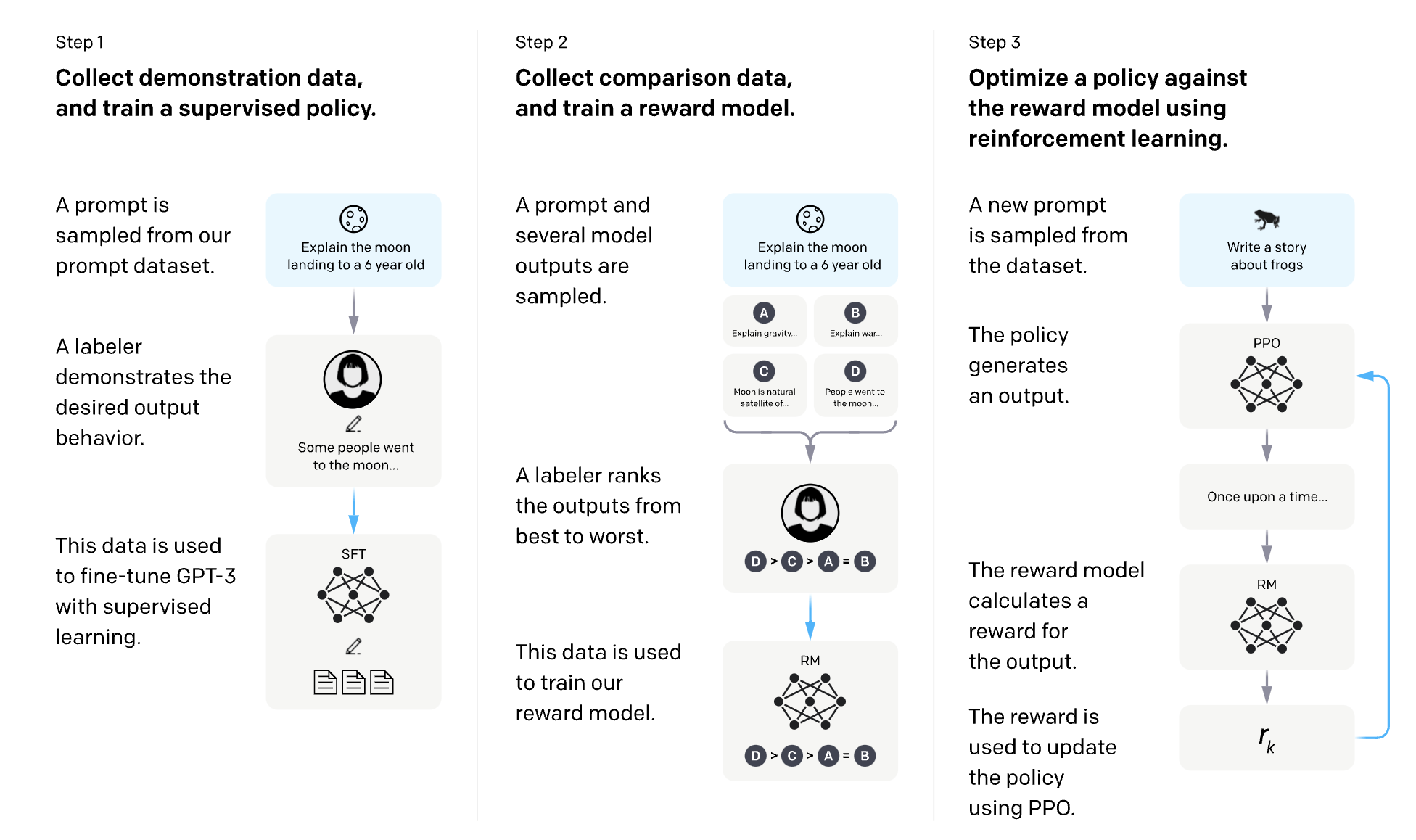
Les LLM utilisant RLHF apprennent de leurs interactions directes avec les utilisateurs… et vous pouvez probablement déjà voir où cela va pour le LLMO black hat.
Ils peuvent apprendre de :
- Les conversations réelles qu'ils ont (y compris les conversations historiques)
- Les notes positives/négatives que les utilisateurs attribuent aux réponses
- La sélection qu'un utilisateur fait lorsque le LLM présente plusieurs options
- Les détails du compte de l'utilisateur ou d'autres données personnalisées auxquelles le LLM a accès
Par exemple, voici une conversation dans ChatGPT qui indique qu'il a appris (et ensuite adapté son comportement futur) en fonction de la conversation directe qu'il a eue avec cet utilisateur :
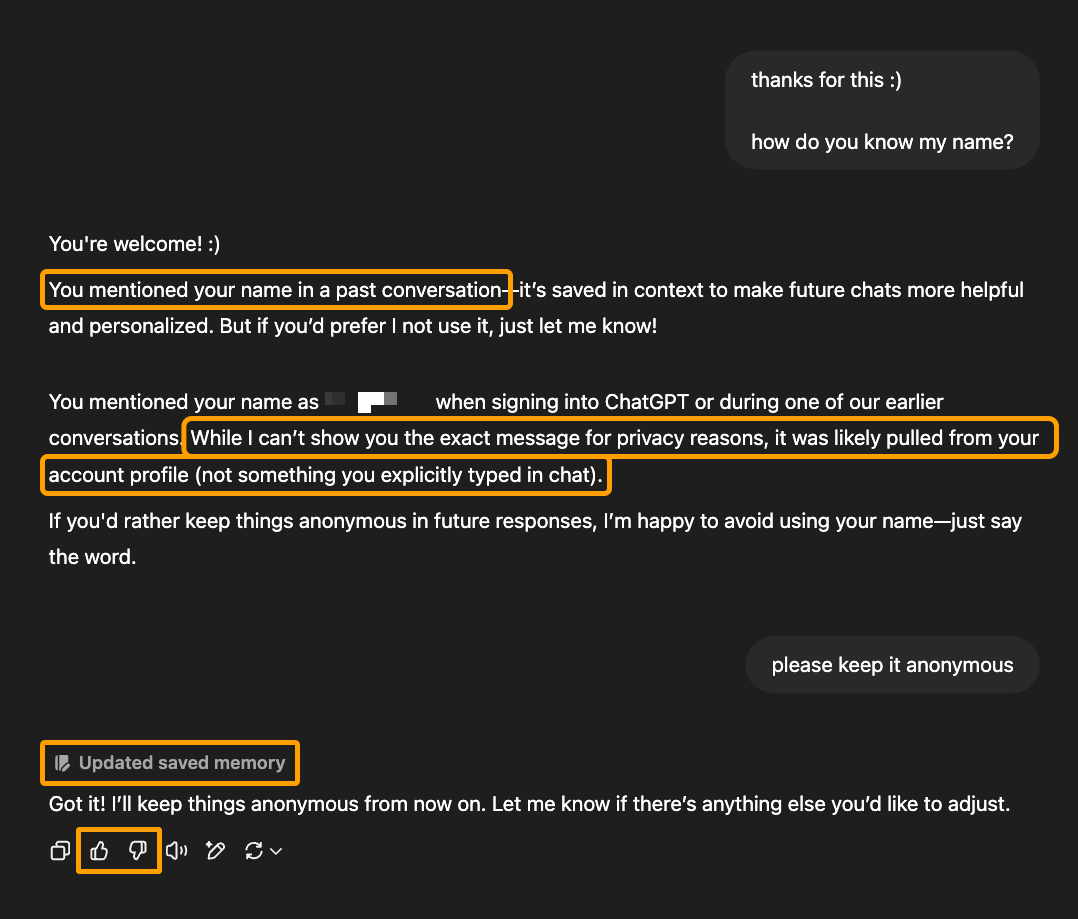
Maintenant, cette réponse présente quelques problèmes : la réponse se contredit, l'utilisateur n'a pas mentionné son nom dans les conversations précédentes et ChatGPT ne peut pas utiliser la raison ou le jugement pour déterminer avec précision où et comment il a appris le nom de l'utilisateur.
Il n'en demeure pas moins que ce LLM a appris quelque chose qu'il n'aurait pas pu obtenir uniquement par les données d'entraînement et la recherche. Il n'a pu l'apprendre que par son interaction avec cet utilisateur.
Et c’est exactement la raison pour laquelle il est facile de manipuler ces signaux.
Il est certainement possible que, de la même manière que Google utilise une classification « votre argent, votre vie » pour le contenu qui pourrait causer un réel préjudice aux chercheurs, les LLM accordent plus d'importance à des sujets ou types d'informations spécifiques.
Contrairement à la recherche Google traditionnelle, qui dispose d'un nombre considérablement plus petit de facteurs de classement, les LLM disposent d'illions (millions, milliards ou billions) de paramètres à ajuster pour différents scénarios.
| Modèle | Paramètres |
|---|---|
| GPT-1 | ~117 millions |
| GPT-2 | ~1,5 milliard |
| GPT-3 | ~175 milliards |
| GPT-4 | ~1,76 billion |
| GPT-5 | ~17,6 billions (spéculatif) |
Par exemple, l'exemple ci-dessus concerne la confidentialité des utilisateurs, un sujet qui aurait plus d'importance et de poids que d'autres. C'est probablement la raison pour laquelle le LLM aurait pu procéder à ce changement immédiatement.
Heureusement, il n'est pas aussi simple de forcer un LLM à apprendre d'autres choses, comme l'équipe de Reboot l'a découvert lors de tests pour ce type exact de manipulation RLHF.

Il y a une limite ténue qui, une fois franchie, empoisonne le bien de tous. Ceci m'amène au deuxième comportement fondamental du LLMO black hat…
2. Empoisonnement des ensembles de données utilisés par les LLM
Permettez-moi de mettre en lumière le mot « poison » pendant un instant, car je ne l’utilise pas pour un effet dramatique.
Les ingénieurs utilisent ce langage pour décrire la manipulation des ensembles de données de formation LLM comme un « empoisonnement de la chaîne d’approvisionnement ».
Certains référenceurs le font intentionnellement. D'autres suivent simplement des conseils qui semblent judicieux, mais qui sont dangereusement erronés.
Vous avez probablement vu des publications ou entendu des suggestions telles que :
- « Vous devez intégrer votre marque dans les données de formation LLM. »
- « Utilisez l'ingénierie des fonctionnalités pour rendre vos données brutes plus adaptées au LLM. »
- « Influencez les modèles dont les LLM s'inspirent pour favoriser votre marque. »
- « Publiez des articles récapitulatifs vous désignant comme le meilleur, afin que les LLM s'en inspirent. »
- « Ajoutez du contenu sémantiquement riche en reliant votre marque à des termes de haute autorité. »
J'ai demandé à Brandon Li, ingénieur en apprentissage automatique chez Ahrefs, comment les ingénieurs réagissent face à l'optimisation de la visibilité des données utilisées par les masters de maîtrise et les moteurs de recherche. Sa réponse a été directe :
S'il vous plaît, ne faites pas cela, cela perturbe l'ensemble de données. Brandon Li, Ingénieur en apprentissage automatique, Ahrefs
La différence entre la façon de penser des référenceurs et celle des ingénieurs est importante. Intégrer un ensemble de données d'entraînement n'est pas comparable à être indexé par Google. Ce n'est pas quelque chose que vous devriez essayer de manipuler pour y parvenir.
Prenons l’exemple du balisage de schéma utilisé par les ingénieurs de recherche d’ensembles de données.
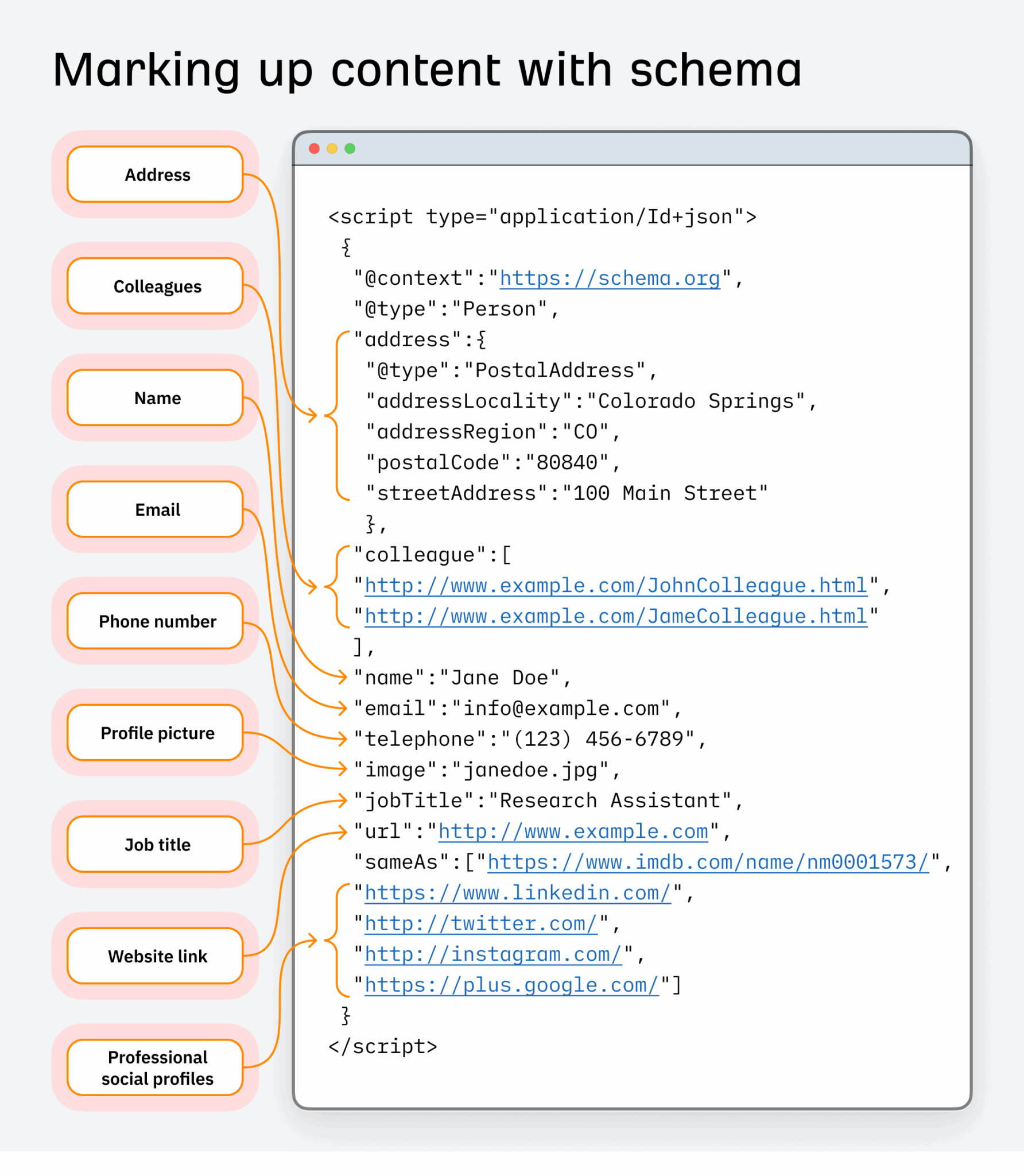
En SEO, il est utilisé depuis longtemps pour améliorer la façon dont le contenu apparaît dans la recherche et améliorer les taux de clics.
Mais il y a une ligne fine entre l'optimisation et l'abus du schéma, en particulier lorsqu'il est utilisé pour forcer des relations d'entité qui ne sont pas exactes ou méritées.
Lorsqu'un schéma est mal utilisé à grande échelle (que ce soit délibérément ou simplement par des praticiens incompétents suivant de mauvais conseils), les ingénieurs perdent totalement confiance dans la source de données. Celle-ci devient confuse, peu fiable et inadaptée à l'apprentissage.
Si l'objectif est de manipuler les résultats du modèle en corrompant les données d'entrée, il ne s'agit plus de SEO. Cela empoisonne la chaîne d'approvisionnement.
Ce n’est pas seulement un problème de référencement.
Les ingénieurs considèrent l’empoisonnement des ensembles de données comme un risque de cybersécurité, avec des conséquences concrètes.
Prenons l'exemple de Mithril Security, une entreprise axée sur la transparence et la confidentialité en IA. Son équipe a réalisé un test pour démontrer la facilité avec laquelle un modèle pouvait être corrompu par des données empoisonnées. Le résultat a été PoisonGPT , une version falsifiée de GPT-2 qui répétait avec assurance les fausses informations insérées dans son ensemble d'entraînement.
Leur objectif n'était pas de diffuser de fausses informations, mais de démontrer qu'il est facile de compromettre la fiabilité d'un modèle si le pipeline de données n'est pas protégé.
Au-delà des spécialistes du marketing, les types d’acteurs malveillants qui tentent de manipuler les données de formation incluent les pirates informatiques, les escrocs, les distributeurs de fake news et les groupes à motivation politique visant à contrôler les informations ou à déformer les conversations.
Plus les référenceurs s’engagent dans la manipulation des ensembles de données, intentionnellement ou non, plus les ingénieurs commencent à nous considérer comme faisant partie du même ensemble de problèmes.
Non pas comme des optimiseurs, mais comme des menaces pour l'intégrité des données.
Pourquoi accéder à un ensemble de données n'est de toute façon pas le bon objectif à atteindre
Parlons chiffres. Lors de l'entraînement de GPT-3 par OpenAI , les données suivantes ont été utilisées :
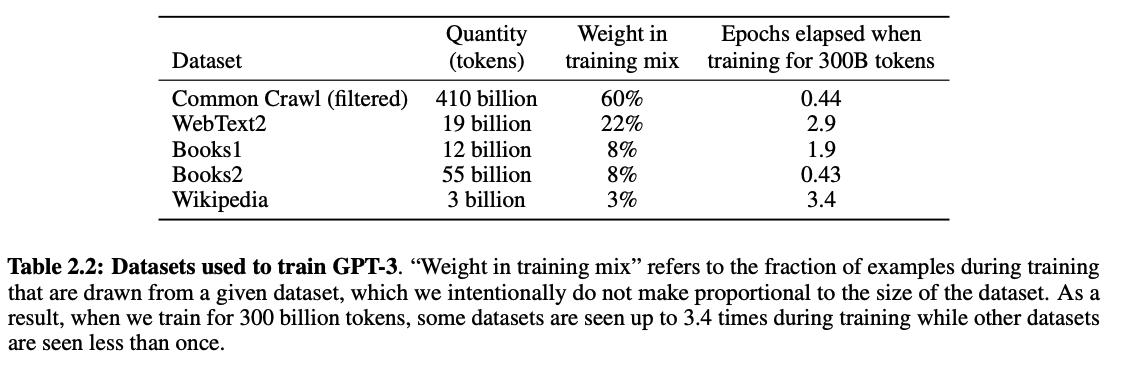
Initialement, 45 To de données CommonCrawl ont été utilisées (environ 60 % du total des données d'entraînement). Cependant, seuls 570 Go (environ 1,27 %) ont été intégrés à l'ensemble d'entraînement final après un nettoyage approfondi des données.
Qu'est-ce qui a été gardé ?
- Pages qui ressemblent à du matériel de référence de haute qualité (pensez à des textes académiques, à de la documentation de niveau expert, à des livres)
- Contenu qui n'a pas été dupliqué dans d'autres documents
- Une petite quantité de contenu fiable et sélectionné manuellement pour améliorer la diversité
Bien qu'OpenAI n'ait pas fourni de transparence pour les modèles ultérieurs, des experts comme le Dr Alan D. Thompson ont partagé certaines analyses et informations sur les ensembles de données utilisés pour entraîner GPT-5 :

Cette liste comprend des sources de données beaucoup plus ouvertes à la manipulation et plus difficiles à nettoyer, comme les publications Reddit, les commentaires YouTube et le contenu Wikipédia, pour n'en citer que quelques-unes.
Les ensembles de données continueront d'évoluer avec les nouvelles versions de modèles. Cependant, nous savons que les ensembles de données considérés comme de meilleure qualité par les ingénieurs sont échantillonnés plus fréquemment lors du processus d'apprentissage que les ensembles de données de moindre qualité et « bruyants ».
Étant donné que GPT-3 a été formé sur seulement 1,27 % des données CommonCrawl et que les ingénieurs sont de plus en plus prudents avec le nettoyage des ensembles de données, il est incroyablement difficile d'insérer votre marque dans le matériel de formation d'un LLM.
Et si c’est ce que vous recherchez, alors en tant que référenceur, vous passez à côté de l’essentiel.
La plupart des masters en droit (LLM) enrichissent désormais leurs réponses grâce à une recherche en temps réel. En réalité, ils effectuent davantage de recherches que les humains.
Par exemple, ChatGPT a effectué plus de 89 recherches en 9 minutes pour l'une de mes dernières requêtes :

En comparaison, j'ai suivi l'une de mes expériences de recherche lors de l'achat d'un découpeur laser et j'ai effectué 195 recherches en plus de 17 heures dans le cadre de mon parcours de recherche global.
Les LLM effectuent des recherches plus rapides, plus approfondies et plus larges que n'importe quel utilisateur individuel, et citent souvent plus de ressources que celles sur lesquelles un chercheur moyen cliquerait normalement lorsqu'il recherche simplement une réponse sur Google.
Apparaître dans les réponses en faisant un bon référencement (au lieu d'essayer de pirater les données de formation) est la meilleure voie à suivre ici.
Un moyen simple d'évaluer votre visibilité est de consulter les analyses Web d'Ahrefs :
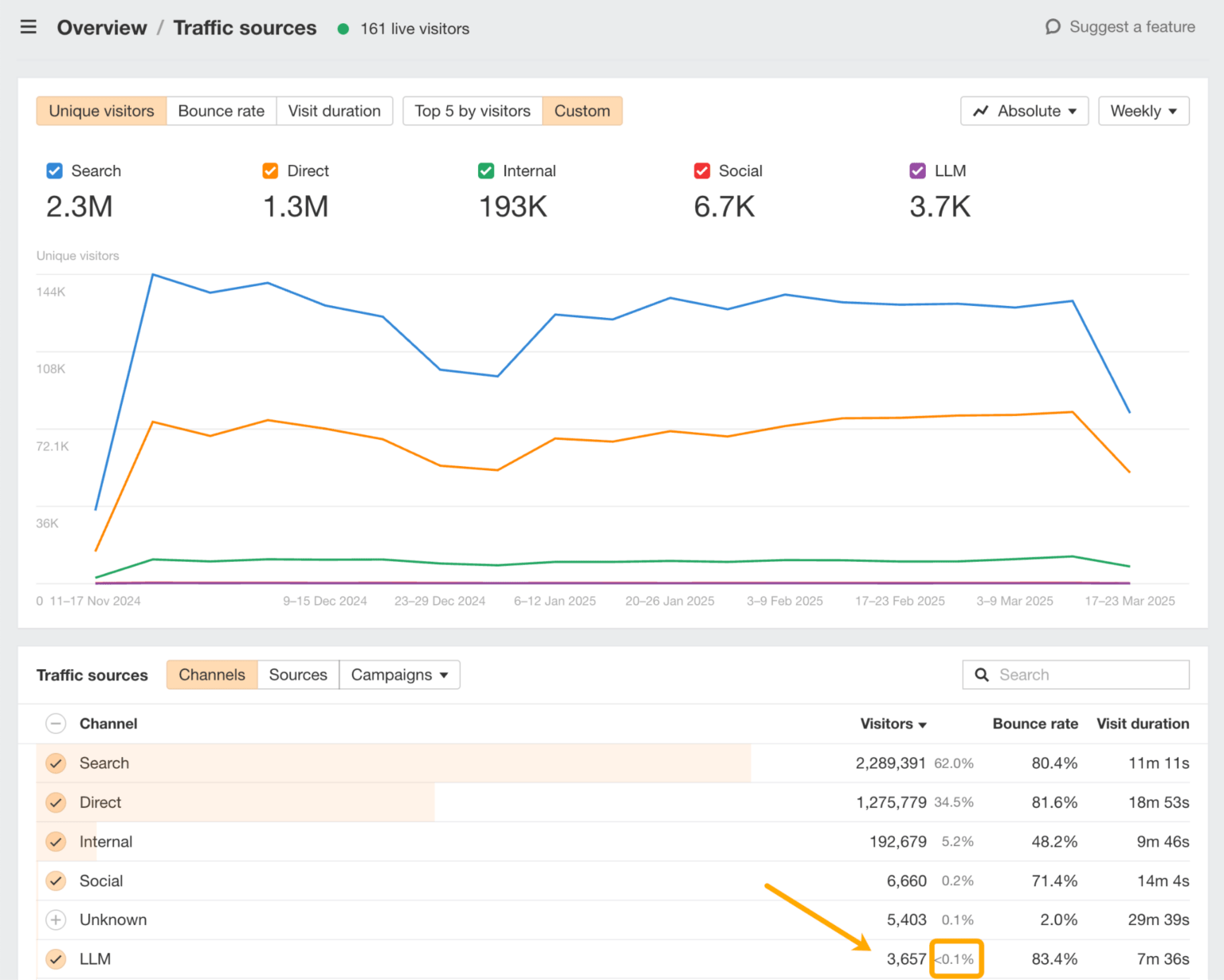
Ici, vous pouvez analyser exactement quels LLM génèrent du trafic vers votre site et quelles pages apparaissent dans leurs réponses.
Cependant, il pourrait être tentant de commencer à optimiser votre contenu avec un texte « riche en entités » ou une formulation plus « adaptée aux LLM » pour améliorer sa visibilité dans les LLM, ce qui nous amène au troisième modèle de LLMO black hat.
3. Sculpter des modèles de langage à des fins égoïstes
Le comportement final contribuant au LLMO black hat consiste à sculpter des modèles de langage pour influencer les réponses LLM basées sur la prédiction.
Ce concept est similaire à ce que les chercheurs de Harvard appellent dans cette étude « séquences de texte stratégiques » . Il s'agit de textes injectés sur des pages web dans le but précis d'influencer des mentions plus favorables de marques ou de produits dans les réponses aux LLM.
Le texte rouge ci-dessous en est un exemple :

Le texte rouge est un exemple de contenu injecté sur une page de produit de commerce électronique afin de l'afficher comme le premier choix dans les réponses LLM pertinentes.
Même si l’étude s’est concentrée sur l’insertion de chaînes de texte générées par machine (et non sur des textes marketing traditionnels ou du langage naturel), elle a néanmoins soulevé des préoccupations éthiques concernant l’équité, la manipulation et la nécessité de mesures de protection, car ces modèles conçus exploitent le mécanisme de prédiction de base des LLM.
La plupart des conseils que je vois de la part des référenceurs pour obtenir une visibilité LLM entrent dans cette catégorie et sont représentés comme un type de référencement d'entité ou de référencement sémantique .
Sauf que maintenant, au lieu de parler de mettre des mots-clés partout, ils parlent de mettre des entités partout pour l'autorité thématique .
Par exemple, examinons les conseils SEO suivants d’un point de vue critique :

La phrase réécrite a perdu son sens original, ne transmet pas l'émotion ou l'expérience amusante, perd l'opinion de l'auteur et change complètement le ton, la faisant paraître plus promotionnelle.
Pire encore, cela n’attire pas non plus un lecteur humain.
Ce type de conseils incite les experts SEO à organiser et à signaler les informations destinées aux LLM dans l'espoir qu'elles soient mentionnées dans les réponses. Et dans une certaine mesure, cela fonctionne.
Cependant, cela fonctionne (pour l'instant) car nous modifions les schémas linguistiques que les LLM sont censés prédire. Nous les rendons volontairement artificiels pour satisfaire un algorithme ou un modèle, au lieu de les écrire pour des humains… Cela vous rappelle-t-il aussi un sentiment de déjà-vu SEO ?
D’autres conseils qui suivent cette même ligne de pensée incluent :
- Augmenter les cooccurrences d'entités : comme réécrire le contenu entourant les mentions de votre marque pour inclure des sujets ou des entités spécifiques auxquels vous souhaitez être fortement connecté.
- Positionnement artificiel de la marque : comme faire en sorte que votre marque soit présentée dans davantage de publications récapitulatives « best of » pour améliorer l’autorité (même si vous créez ces publications vous-même sur votre site ou en tant que publications invitées).
- Contenu de questions-réponses riche en entités : comme transformer votre contenu en un format de questions-réponses résumable avec de nombreuses entités ajoutées à la réponse, au lieu de partager des histoires, des expériences ou des anecdotes engageantes.
- Saturation
de l'autoritéthématique : comme publier une quantité écrasante de contenu sur tous les angles possibles d'un sujet pour dominer les associations d'entités.
Ces tactiques peuvent influencer les LLM, mais elles risquent également de rendre votre contenu plus robotique, moins fiable et finalement oubliable.
Il est néanmoins utile de comprendre comment les LLM perçoivent actuellement votre marque, surtout si d’autres façonnent ce récit pour vous.
C'est là qu'intervient un outil comme Brand Radar d'Ahrefs. Il vous aide à voir à quels mots-clés, fonctionnalités et groupes de sujets votre marque est associée dans les réponses de l'IA.

Ce type de perspicacité consiste moins à jouer avec le système qu’à repérer les angles morts dans la façon dont les machines vous représentent déjà.
Si nous nous engageons sur la voie de la manipulation des modèles linguistiques, cela ne nous apportera pas les avantages que nous souhaitons, et ce pour plusieurs raisons.
Pourquoi jouer avec le système avec le LLMO black hat va se retourner contre vous
Contrairement au référencement, la visibilité LLM n'est pas un jeu à somme nulle. Ce n'est pas un bras de fer où si une marque perd son classement, c'est parce qu'une autre a pris sa place.
Nous pouvons tous devenir perdants dans cette course si nous ne faisons pas attention.
Les masters en droit n'ont pas besoin de mentionner ni de lier des marques (et c'est souvent le cas). Cela s'explique par le processus de réflexion dominant en matière de création de contenu SEO. Voici à quoi cela ressemble :
- Faire une recherche de mots clés
- Rétro-ingénierie des articles les mieux classés
- Placez-les dans un optimiseur sur la page
- Créer un contenu similaire, correspondant au modèle des entités
- Publiez du contenu qui suit le modèle de ce qui est déjà classé
Ce que cela signifie, dans le grand schéma des choses, c’est que notre contenu peut être ignoré. Vous souvenez-vous du processus de nettoyage des données d'entraînement LLM ? L'un des éléments clés était la déduplication au niveau du document . Cela signifie que les documents qui contiennent le même message ou qui n'apportent pas d'informations nouvelles et pertinentes sont supprimés des données d'entraînement.

Une autre façon d’envisager cela est d’envisager la question sous l’angle de la « saturation des entités ».
En recherche qualitative universitaire, la saturation des entités désigne le point où la collecte de données supplémentaires pour une catégorie d'informations particulière ne révèle aucun nouvel éclairage. En résumé, le chercheur a atteint un point où il observe des informations similaires de manière répétée.
C'est à ce moment-là qu'ils savent que leur sujet a été exploré en profondeur et qu'aucun nouveau modèle n'émerge.
Et bien, devinez quoi ?
Notre formule actuelle et nos meilleures pratiques SEO pour créer du contenu « riche en entités » conduisent les LLM à ce point de saturation plus rapidement, rendant une fois de plus notre contenu ignorable.
Cela permet également de synthétiser notre contenu sous forme de méta-analyse. Si 100 articles abordent un sujet de manière identique (en termes d'essence même de ce qu'ils communiquent) et qu'il s'agit d'informations assez génériques, de type Wikipédia, aucun d'entre eux ne sera cité. [NDLR : cela devient donc une technique de negative GEO pour tuer vos concurrents]
Rendre notre contenu résumable ne facilite pas les mentions ou les citations. Pourtant, c'est l'un des conseils les plus courants des meilleurs référenceurs pour gagner en visibilité dans les réponses des LLM.
Alors, que pouvons-nous faire à la place ?
Comment améliorer intelligemment la visibilité de votre marque dans les LLM
Ma collègue Louise a déjà créé un guide génial sur l'optimisation de votre marque et de votre contenu pour la visibilité dans les LLM (sans recourir à des tactiques de black hat).
Lectures complémentaires
Au lieu de répéter les mêmes conseils, je voulais vous laisser un cadre sur la façon de faire des choix intelligents à mesure que nous avançons et que vous commencez à voir de nouvelles théories et modes apparaître dans LLMO.
Et oui, celui-ci est là pour l'effet dramatique, mais aussi parce qu'il simplifie les choses, vous aidant à contourner les pièges du FOMO en cours de route.
Cela vient des 5 lois fondamentales de la stupidité humaine de l'historien économique italien, le professeur Carlo Maria Cipolla.
Allez-y, ricanez, puis faites attention. C'est important.
Selon le professeur Cipolla, l’intelligence se définit comme le fait d’entreprendre une action qui profite à soi-même et aux autres simultanément, créant ainsi une situation gagnant-gagnant.
C'est en opposition directe avec la stupidité, qui est définie comme une action qui crée des pertes pour vous-même et pour les autres :
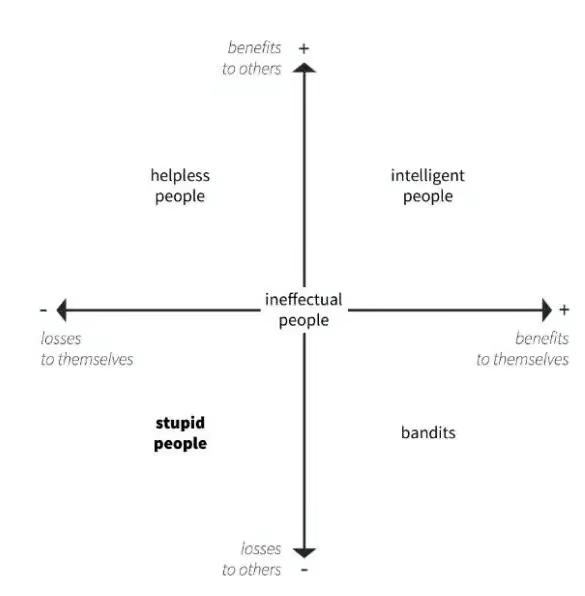
Dans tous les cas, les pratiques de black hat se situent clairement dans les quadrants inférieur gauche et inférieur droit.
Les bandits du référencement, comme j’aime à les appeler, sont les personnes qui ont utilisé des tactiques d’optimisation manipulatrices pour des raisons égoïstes (avantages pour eux-mêmes)… et qui ont ainsi ruiné Internet (pertes pour les autres).
Par conséquent, les règles du référencement et du LLMO à l’avenir sont simples.
- Ne sois pas stupide.
- Ne soyez pas un bandit.
- Optimisez intelligemment.
L’optimisation intelligente consiste à se concentrer sur votre marque et à garantir qu’elle est représentée avec précision dans les réponses LLM.
Il s'agit d'utiliser des outils comme AI Content Helper qui sont spécifiquement conçus pour améliorer votre couverture de sujet, au lieu de se concentrer sur l'encombrement de plus d'entités. (Le score SEO ne s'améliore que lorsque vous couvrez les sujets suggérés en détail, et non lorsque vous insérez plus de mots.)
Mais surtout, il s’agit de contribuer à un meilleur Internet en se concentrant sur les personnes que vous souhaitez atteindre et en optimisant pour elles, et non sur des algorithmes ou des modèles linguistiques.
Réflexions finales
Le LLMO en est encore à ses débuts, mais les modèles sont déjà familiers, tout comme les risques.
Nous avons vu ce qui se passe lorsque les tactiques à court terme ne sont pas maîtrisées. Lorsque le SEO est devenu une course vers le bas, nous avons perdu confiance, qualité et créativité. Ne répétons pas cette situation avec les LLM.
Cette fois, nous avons l'occasion de réussir. Cela signifie :
- Ne manipulez pas les modèles de prédiction ; façonnez plutôt la présence de votre marque.
- Ne courez pas après la saturation des entités, mais créez du contenu que les humains veulent lire.
- N'écrivez pas pour être résumé ; écrivez plutôt pour avoir un impact sur votre public.
Parce que si votre marque n'apparaît dans les LLM que lorsqu'elle est dépouillée de sa personnalité, est-ce vraiment une victoire ?



